
Large neural network models dominate natural language processing and computer vision, but their initialization and learning rates often rely on heuristic methods, leading to inconsistency across studies and model sizes. The µ-Parameterization (µP) proposes scaling rules for these parameters, facilitating zero-shot hyperparameter transfer from small to large models. However, despite its potential, widespread adoption of µP is hindered by implementation complexity, numerous variations, and intricate theoretical underpinnings.
Although promising, empirical evidence on the effectiveness of µP at large scales is lacking, raising concerns about hyperparameter preservation and compatibility with existing techniques like decoupled weight decay. While some recent works have adopted µP, open questions remain unresolved, prompting further investigation.
The µP proposed within the Tensor Programs series demonstrated zero-shot hyperparameter transfer, yet concerns arose regarding stability and scalability for large-scale transformers. Recent works explored hyperparameter tuning with µP but lacked evidence of its efficacy for large models. Some suggest using µ-Transfer to avoid large-scale experiments, while others propose alternative methods like scaling laws based on computing budget or architectural adjustments. Automatic Gradient Descent and Hypergradients offer complex alternatives for learning rate tuning but may lack affordability compared to µP.
The researcher investigates µP for transformers concerning width. The µP enables hyperparameter transfer from small to large models, focusing on width for transformers. It presents scaling rules for initialization variance and Adam learning rates. The paper assumes specific values for model parameters and follows scaling rules based on the base learning rate α. Also, it adjusts the attention scale τ−1 for simplicity, observing its impact on performance and transfer. Overall, µP offers a systematic approach to parameter scaling in neural networks.
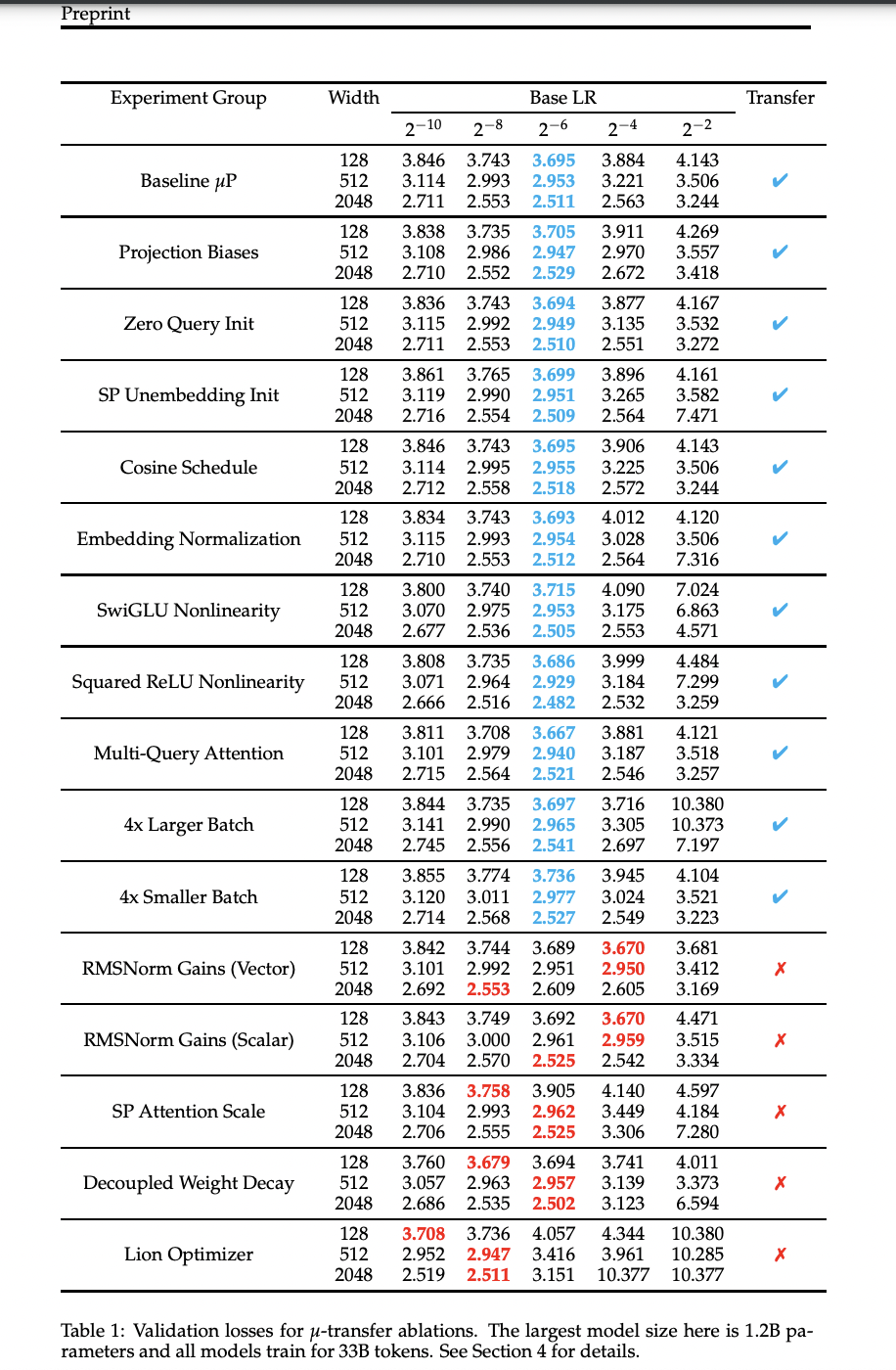
The RMSNorm ablation tests the efficacy of trainable scale vectors (‘gains’) and their impact on learning rate transferability under µP. Results show unreliable transfer of optimal learning rates with Θ(1) scaling for gains, negatively affecting model quality in large µP models. Zero-initialized query projections enhance transfer and slightly improve loss. Using the standard attention scale harms performance. Multiplicative nonlinearities allow transfer despite potential interference. Lion optimizer fails to transfer base learning rates, while multi-query attention remains compatible. Large-scale experiments confirm µ-Transfer’s effectiveness, predicting optimal learning rates even at significantly larger scales, suggesting minimal interference from emergent outliers.
To conclude, This research evaluated µ-Transfer’s reliability in transferring learning rates for transformers. µP succeeded in most scenarios, including various architectural modifications and batch sizes. However, it failed to transfer when using trainable gain parameters or excessively large attention scales. The simple µP approach outperformed the standard parameterization for transformers. Notably, µ-Transfer accurately predicted optimal learning rates from a small to a vastly larger model. These findings contribute to hyperparameter transfer research, potentially inspiring further exploration in the field.